Anatomy of a Collection; Dissecting CPA
Prior posts in this series have discussed the Crunchy Postgres via Automation product, the team behind it, and some of our processes and tooling. This week, we’re going to dive into the collection itself.
Collection? Yes, the CPA product is really an Ansible collection. To quote the docs:
Collections are a distribution format for Ansible content. You can package and distribute playbooks, roles, modules, and plugins using collections. A typical collection addresses a set of related use cases. For example, the cisco.ios collection automates management of Cisco IOS devices.
The CPA product, or crunchydata.pg collection, is a set of roles, modules, and sample playbooks and inventories created to automate the deployment of Postgres clusters. It can stand up a single-node, non-highly-available Postgres instance, a multi-node replicated Postgres instance, and a multi-node highly-available Postgres instance. And because we believe in complete solutions at Crunchy Data, the collection also includes several auxiliary components as well.
Let’s take a look at the whole collection first:
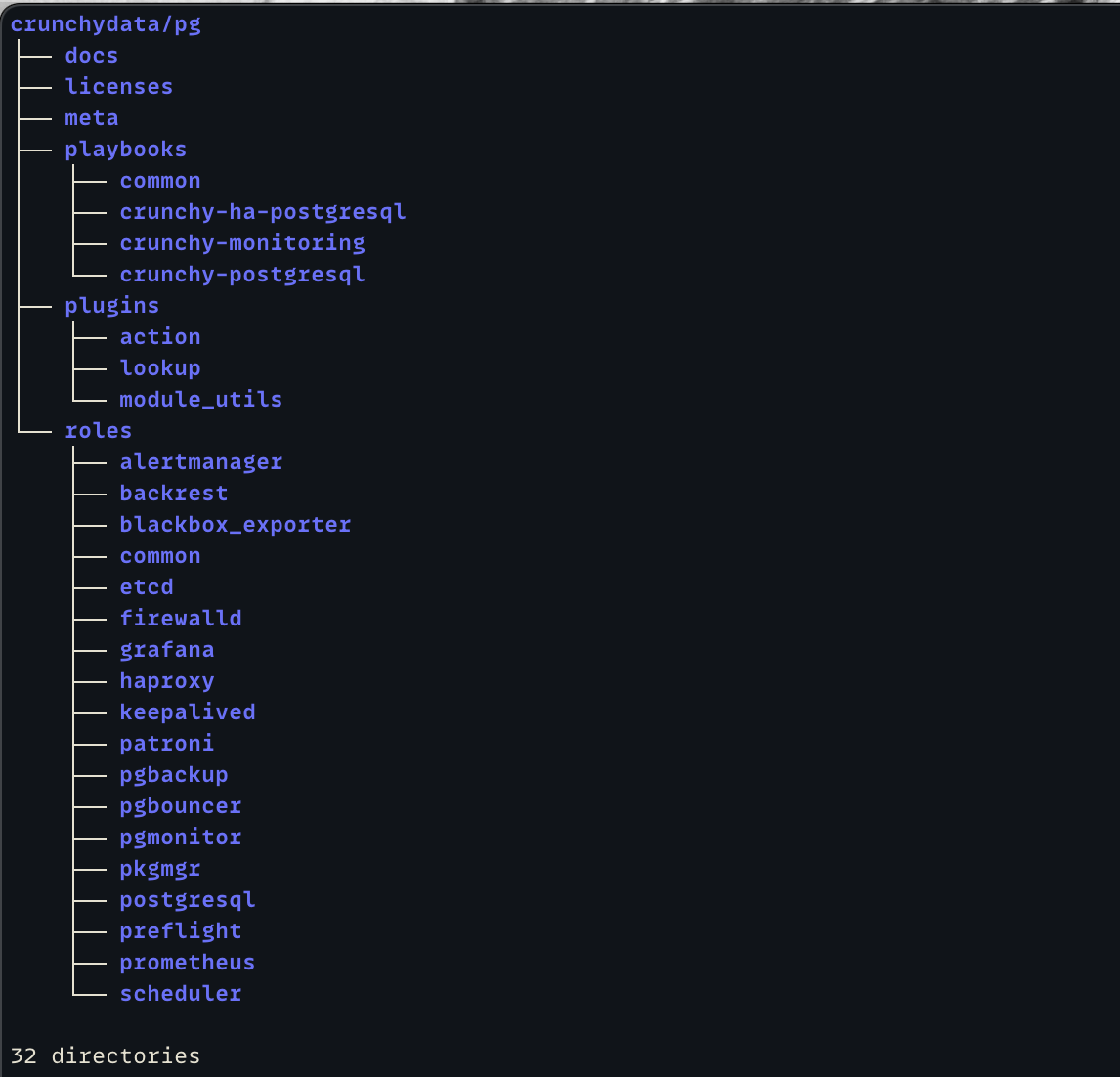
The first three entries are typical Ansible collection stuff so we won’t go over those. Next up, you can see that we ship several example playbooks as part of our collection. These playbooks are broken up into four sections: one each for playbooks specific to highly-available clusters, one for non-highly-available clusters, one for playbooks that are common across both highly-available and non-highly-available clusters, and finally playbooks specific to deploying pgMonitor separately (we deploy pgMonitor by default as part of our highly-available clusters).
Not shown, our playbooks directories also include example Ansible inventories as well as group_vars. While most customers will alter these example playbooks and inventories, or write their own from scratch, we believe in shipping fully functional examples as part of the collection for reference. Additionally, we use these examples for our own internal testing, guaranteeing they are fully functional and reflect our recommended best practices with the current collection.
Next up, we include a sole Python module as part of the collection currently. It’s not intended for use by customers directly, but our roles make use of it directly. It’s a fairly simple module and works well enough, but if my planned refactoring (which I’ll discuss in a later post) happens then it’ll be removed. So let’s not dwell on it now.
Finally, we come to the collection’s roles, which are the heart of the product. As you can see, we currently have eighteen roles in the collection! Which honestly seems like a lot, but I already have plans in the near term to break some of the existing roles up into more targeted roles, and want to add a new component entirely which will get it’s own role. We’re working really hard at applying the Unix philosophy of ‘do one thing and do it well’ to our roles, so while juggling all these can be a bit much at times, we feel the trade-off is worth it.
Most of these will be self-evident, but let’s dive into these roles, shall we?
- alertmanager
- This role is responsible for (optionally) installing Alertmanager, setting up notification channels, and configuring alerting rules so that you know what is going on with your Crunchy Postgres cluster at all times. This role even supports running multiple Alertmanager nodes in their own highly-available configuration.
- backrest
- This role is responsible for installing pgBackRest, configuring the backup repository, and executing any requested backups/restores.
- blackbox_exporter
- A sub-component of pgMonitor, this role is responsible for optionally deploying the Prometheus blackbox_exporter onto monitored nodes and configuring Prometheus to report on its metrics.
- common
- An 'internal' role that the other roles depend on. Due to the *intricacies* of the twenty-two level Ansible variable hierarchy, this role was born out of a need to make cross-role access to certain variables easier. Its use has expanded since then, and it now handles those things that "should be set up for all other roles to find/use later". This role is not designed for users to make use of it.
- etcd
- This role is responsible for installing etcd, configuring the etcd nodes to talk to each other, and then setting up the DCS for Patroni. You could say this role and the Patroni role are the 'heart' of our highly-available clusters.
- firewalld
- One of those 'auxiliary' pieces mentioned above, the firewalld role will optionally install and configure firewalld on nodes of the cluster, adding the appropriate allow rules as needed for components to talk to each other. Not strictly needed by the CPA product, but as Crunchy Data believes strongly in best practices and system security, this role was added to reduce the friction for our users in deploying security-conscious configurations.
- grafana
- Responsible for (optionally) installing Grafana and setting up the default dashboards shipped with pgMonitor, this role works both with an existing Grafana install or a new CPA-installed Grafana.
- haproxy
- HAproxy is used in CPA to route incoming connections to the current Patroni leader (or a follower, depending on what connection type you asked for) without the client/application needing to know the status of the Patroni cluster. This role will install the proxy and configure the appropriate front-end and back-end stanzas based on your deployment choices.
- keepalived
- Another 'auxiliary' role not strictly needed by CPA itself, the keepalived role exists to make deploying services that aren't highly-available by themselves fault tolerant. For example, once can deploy multiple HAProxy nodes and then have the keepalived role set up and maintain a virtual IP (VIP) to 'float' between them. This role was created based on feedback from customers and has since found fairly widespread use 'in the field'.
- patroni
- Obviously *the* linchpin in our highly-available deployments, this role installs and configures Patroni such that it can connect to and monitor the health of the Crunchy Postgres nodes, record said state in the etcd DCS, perform switchover/failover operations, and rebuild/resurrect failed nodes.
- pgbackup
- This role was a mistake and is something I'm going to kill at the first opportunity. This role's original intent was to be a singe point of entry for handling any kind of physical or logical backup a user might want. The role works well enough, but having a whole role that basically acts as a redirection into the backrest and postgresql roles tasks just seems ridiculous when our playbooks can already abstract that away.
- pgbouncer
- Responsible for installing, configuring, and starting PgBouncer to manage our inbound connection pool, this role is fairly clever in that it configures PgBouncer with two entries for each database in the CPA cluster; one of the entries is for 'rw' traffic and the other for 'ro' traffic. These separate pools point at the respective HAProxy front-ends and route you transparently to the current Patroni leader or to one of the followers as requested. If I can get the time to make it happen, we will be adding support for PgCat in 2025, and then dropping both this role and HAProxy in favor of PgCat in 2026.
- pgmonitor
- Probably my least favorite of all the roles (sorry Keith), not because there's anything wrong with the role, but because it does too much IMHO. This role is responsible for every pgMonitor component that doesn't currently have it's own role as well as (re)configuring all the pgMonitor bits to work together. I fully intend for this role to die soon, replaced by individual roles for each and every component of pgMonitor.
- pkgmgr
- The star of CPA 2.x, this role is responsible for working with our BoMs, configuring hosts with local software repositories and handling any package operations (installs, upgrades, removals). It's our newest role, and probably one of the better written ones (even if I do say so myself).
- postgresql
- The reason for the entire collection, this is the role that installs, configures, and manages Crunchy Postgres. As mentioned above, it can stand up a single Crunchy Postgres node (as a leader or a follower), it can stand up a cluster of Crunchy Postgres nodes that follow each other (in a non-highly-available manner) and it can stand up a highly-available Crunchy Postgres cluster.
- preflight
- A role designed to be run once at the beginning of a CPA deployment that will inspect your configuration, examine the targets nodes, and theoretically alert you to any issues that might exist. Ideally, this would happen up front, and allow you to rectify things without getting 47% through a deployment and having it blow up on you. This role has been through a few iterations now, mostly because of the extremely poor way that 'meta dependencies' are handled in Ansible. I have plans for another complete refactor of this role that will also kill the Python module we ship (mentioned above).
- prometheus
- Responsible for (optionally) installing and configuring Prometheus as part of our pgMonitor deployment.
- scheduler
- The last of our 'auxiliary' roles, this role was born of a need to standardize scheduling tasks in a CPA clusters (backups, bloat monitoring, etc). With this role, you simply specify if you want to use `cron` or a Systemd timer, give the schedule, and specify the command to run, and we'll add/update/remove the schedule entry. This role could arguably be a set of tasks in the common role, but it see enough use/re-use that it lives as its own entity.
There you have it; the collection as it exists today. Certainly not the largest Ansible collection I’ve ever seen, but also not a trivial collection. The collection today supports RedHat 8 and 9 (and it’s many many clones) as well as Ubuntu Focal and Jammy. Additionally, we always support all five of the current Crunchy Postgres releases. I know there are plenty of things the collection doesn’t do, or “should” do differently, but I’m pretty pleased with what it does support and how adaptable it is.
Next time, we’ll go over some of the interesting things that we do in our roles. Until then, feel free to hit me up at @hunleyd@fosstodon.org if there’s something specific you’d like me to write about in this series.
:wq